The End of the Flat-Rate Era: Why GitHub Copilot’s Shift to Token Pricing Matters for Every Developer
For years, software engineers and development teams enjoyed a remarkably predictable relationship with AI assistance. You paid your fixed monthly fee, booted up your IDE, and let your AI assistant generate endless lines of boilerplate code, refactor messy functions, and debug tricky scripts. There was no meter running. It was an all-you-can-eat compute buffet.
That era has officially come to an end.
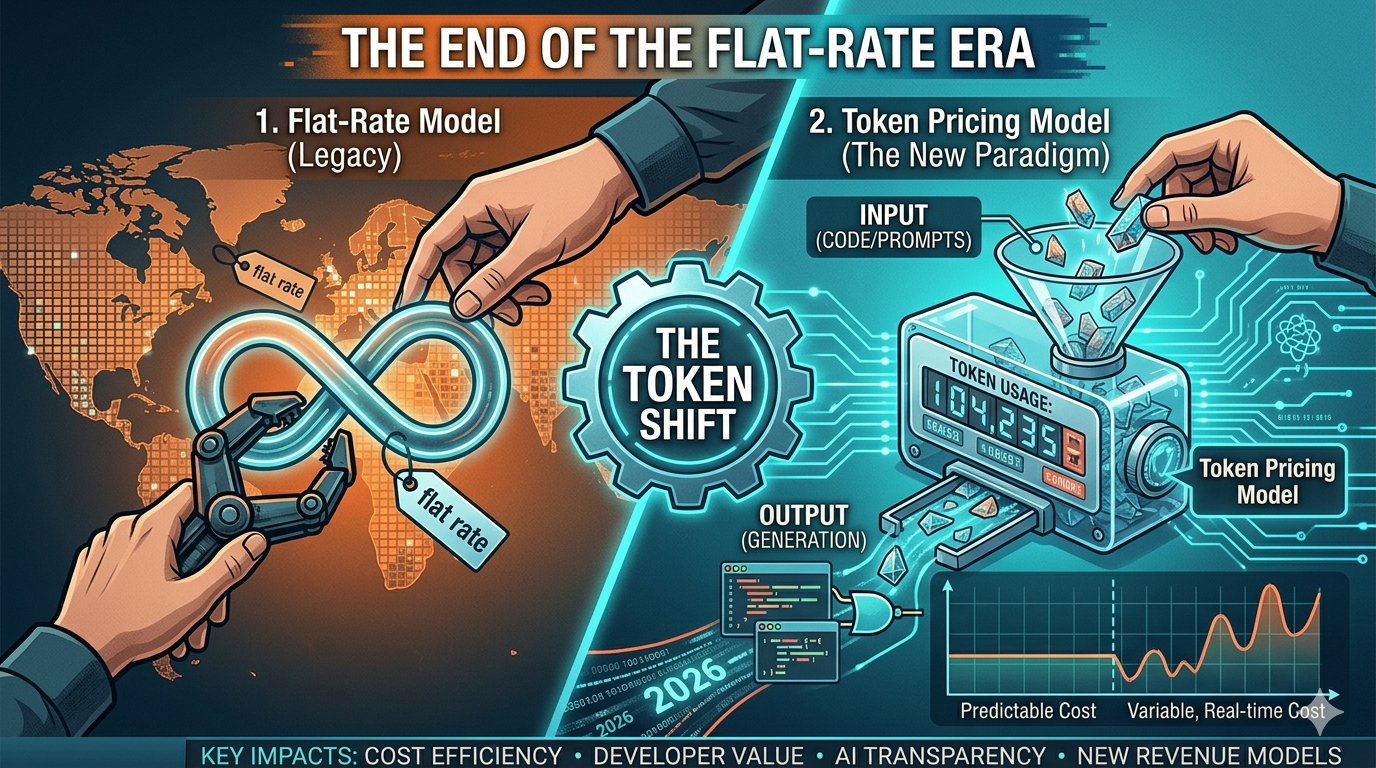
Microsoft has fundamentally changed the economic model of AI-assisted development by transitioning GitHub Copilot to a usage-based token pricing model, completely replacing the flat-rate subscription framework that standard Copilot Pro and enterprise users had grown accustomed to.
Under the new structure, users receive a baseline allotment of monthly credits ($10 for Copilot Pro; $39 for Copilot Pro+), but every single interaction—from a simple autocomplete tab to complex, agentic multi-file code refactoring—now directly consumes tokens from that budget. Once your credits run dry, you pay for exactly what you compute.
This move is a massive structural indicator of a broader shift in the tech ecosystem. As AI transitions from a basic text-generation utility to an autonomous, resource-heavy execution engine, the industry is forcing developers and tech leads to confront the real, raw cost of compute.
The Core Catalyst: The Heavy Compute Toll of Agentic AI
Microsoft’s justification for this pricing pivot highlights the changing nature of the tool itself. Copilot is no longer just an advanced version of autocomplete. It has evolved into a suite of sophisticated, multi-turn AI coding agents capable of executing deeply integrated workflows:
Running automated, end-to-end codebase reviews.
Simulating runtime environments to actively debug complex microservices.
Orchestrating multi-file structural refactoring across complex architectures.
These complex, multi-step actions require immensely higher compute resources than a simple single-line suggestion. When an AI agent scans a repository of dozens of interconnected files to refactor a state management system, it creates massive context windows that send token consumption skyrocketing.
[Old Subscription Model] ───► Unlimited Usage ───► Predictable Cost ($10-$30/mo) ───► Cloud Provider Absorbs Loss
[New Token Model] ───► Inbound Query ────► Dynamic Token Metering ──────► Pay-Per-Execution Reality
For the hyperscalers providing the hardware, absorbing the massive power and infrastructure costs of power-users running continuous, automated loops was no longer sustainable. Usage-based billing fixes the bottom-line problem by aligning user cost directly with cloud infrastructure expense.
The Developer Dilemma: Budgeting for the Brains
The immediate reaction across engineering communities has exposed a major friction point: unpredictability.
For independent developers, small agencies, and fast-moving startups, the beauty of the old model was budget safety. A fixed operational expenditure meant you could code for eighteen hours straight or let a junior developer experiment with AI prompts without worrying about a surprise bill at the end of the month.
Under a consumption-based token system, every interaction carries an explicit micro-cost. Generating a complex block of code, asking the chat panel to explain an optimized algorithm, or triggering an autonomous agent to build a testing suite now ticks down a meter. For heavy users, this realization is triggering a form of "bill anxiety," prompting teams to evaluate exactly when and how they deploy AI inside their workflows.
Metric / Feature | The Subscription Model (Legacy) | The Token Billing Model (Next-Gen) |
Pricing Predictability | High (Fixed monthly or annual fee) | Variable (Tied explicitly to compute density) |
Best For | Casual coding assistance and autocomplete | Highly targeted, strategic development tasks |
Operational Risk | Under-utilization ("Use it or lose it") | Uncapped overages during heavy sprint cycles |
Optimal Workflow | Continuous, background IDE suggestions | Conscious prompt engineering & structured tasks |
The Strategic Silver Lining: Shifting from Hype to Efficiency
While the immediate transition may feel painful, this shift toward token-metered development introduces a necessary discipline to the software engineering industry: algorithmic efficiency.
When compute is functionally free, developers tend to write lazy prompts, let AI generate massive walls of poorly optimized code, and rely on the model to guess its way through a problem. When every token costs money, the value shifts toward precision. Developers will be incentivized to write cleaner, more context-rich prompts, keep their context windows clean, and use AI strategically rather than reflexively.
Furthermore, this change will likely accelerate the adoption of open-source, locally hosted alternatives. For teams with high-performance workstations, routing basic autocomplete or boilerplate tasks to local, light-weight models while saving your premium cloud-based Copilot tokens for heavy structural orchestration is becoming a highly attractive hybrid setup.
The Bottom Line
Microsoft’s transition to token-based pricing for GitHub Copilot is a clear signal that the initial "customer acquisition" phase of consumer generative AI is wrapping up. The underlying economics of data centers, energy demands, and processor scaling are forcing tech giants to build sustainable monetization frameworks.
For engineering teams, the mandate is clear: it’s time to move beyond the excitement of having an AI sidekick and start building practical, metered operational frameworks that measure the exact cost-to-value ratio of every token consumed.